异步编程小结 - IO 模型
异步编程小结 - IO 模型
基本概念
异步编程通常出现在涉及到 IO 操作(网络、磁盘操作等)的情境中。由于 IO 操作较为耗时,在默认情况下,如果一个进程和线程(对于拥有多个线程的进程)进行了 IO 操作,通常会导致这个线程被阻塞(blocked)进而被挂起,在线程请求的资源准备好之后(例如读取/发送数据完成),这个线程才会重新被设置为 ready 等待执行。线程被阻塞时无法进行其他计算,这导致计算资源无法被最大化利用,甚至在某些单线程应用中,会导致应用直接卡死。为了解决这一问题,我们需要使用“异步”模式。
在涉及异步的编程中有两对经常出现的概念:
同步/异步 (synchronous v.s. asynchronous)
同步和异步表示进程/线程之间(或是用户线程与系统内核之间)的协作方式。
同步:数据的发送和接收方的步调一致,例如发送方需要在确认数据发送成功后,才会继续执行后续的其他逻辑,接收方在确认接收到数据(或发现没有其他可读的数据)后,才可以继续执行
异步:发送和接收方不需要保持一致步调,发送方在发送数据后不需要等待是否发送成功,接收方可能会读取到数据,也可能读取不到
阻塞/非阻塞 (blocking v.s. non-blocking)
阻塞/非阻塞表示线程在进行了一次(IO)操作之后的状态
阻塞:发送或读取数据时,如果没有立即发送或读取成功(大多数情况不会立即成功),线程会被阻塞,在发送或读取完成之前无法进行后续的操作
非阻塞:线程在发起一个发送或读取的操作后,即使操作没有完成,线程也不会被阻塞,可以直接开始执行后续的操作
常见的 IO 模型
下面的模型分类及图片来自《Unix 网络编程》,section 6.2
一次 IO 操作(以网络 IO 为例)可以粗略地分为两个阶段:
- 发送数据:
- 线程中要发送的数据复制到内核空间
- 发送数据到远程
- 接收数据:
- 接收网络数据
- 从内核将数据复制到用户空间(即读取线程的内存)
根据在不同阶段用户线程的行为和状态(是否阻塞,在复制数据时是否使用同步的方法),可以划分出几种常见的 IO 模型:
- 阻塞 IO 模型
- 非阻塞 IO 模型
- IO 复用
- 信号驱动 IO
- 异步 IO
阻塞 IO 模型
阻塞 IO (blocking IO)是默认的 IO 模型,线程在进行 IO 操作时会等待数据就绪,而在此期间线程被阻塞(表现为线程在调用 send/recv 时卡住),不能进行其他任何操作,因此不利于进行高并发的网络 IO,但由于在 send/recv 函数调用返回之后即可以保证数据已经读写完毕,因此在逻辑上最为简单和直观。在阻塞 IO 中,用户线程从发起系统调用开始被阻塞,一直到数据被内核读取并复制带用户空间。由于内核进行数据复制时,用户线程在等待这个操作完成,因此我们可以说这个操作是同步的。
如果希望使用阻塞式 IO 并发地处理多个 socket,一种可行的做法是使用多个线程,每个线程只处理一个 socket。由于线程是调度的基本单位,一个线程被阻塞时并不会影响到其他的线程执行。但需要注意的是,虽然比进程更加轻量,线程依然会占用内存(每个线程有独立的栈空间),并且线程在切换时会有耗时(由内核进行调度,会涉及上下文切换,即 context switching),因此相比后面提到的 IO 复用模型,多线程+阻塞 IO 的模型能承受的并发量通常会更小。
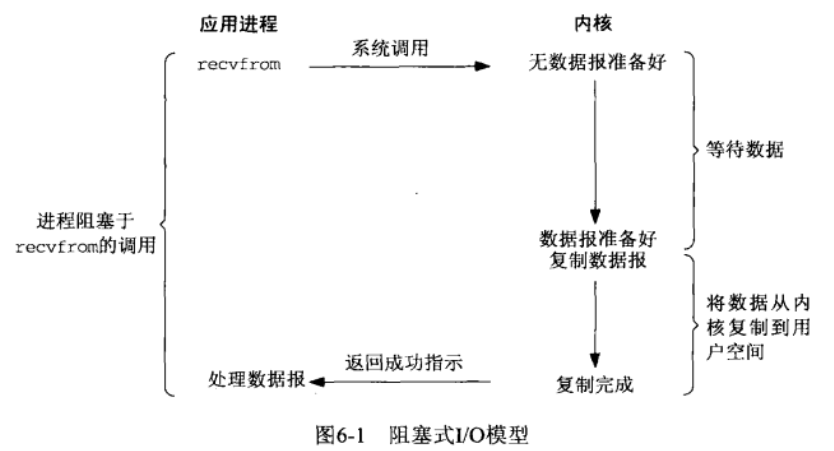
非阻塞 IO 模型
非阻塞 IO (non-blocking IO)与阻塞 IO 的不同点在于,当线程向内核请求读取数据时,如果数据尚未就绪,线程不会被阻塞(即 recv 函数会立即返回),并且线程会收到一个返回值(即图中的 EWOULDBLOCK 错误),表示要读取的数据还没有准备好。如果有网络数据就绪,线程进行 recv 的系统调用会使得内核开始复制接收的数据到线程的内存空间中,在复制结束后 recv 函数才会返回。因此在这样的非阻塞 IO 中,数据的读取依然是同步的。
非阻塞 IO 可以解决阻塞式 IO 无法处理大量并发的 IO 操作的问题,因为在等待数据就绪的时候线程可以执行其他的操作。但是由于不能保证 recv 返回后数据就一定被成功读取,用户线程需要不停检查数据是否就绪,这一做法成为轮询(polling),而通常轮询会浪费大量的 CPU 时间(通常表现为线程将一个 CPU core 占满)。因此在实践中单纯的非阻塞 IO 并不常见。
需要注意的是,虽然系统调用不会阻塞线程,但在数据从内核复制到用户空间(即线程的内存)时,用户线程仍然会进行等待复制完成,因此这个读取数据的操作依然是同步的。
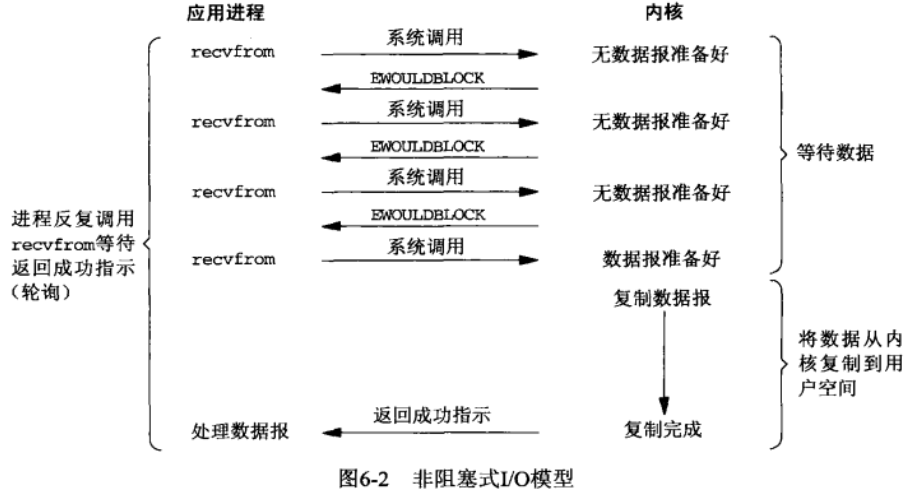
IO 复用模型
IO 复用(IO multiplexing)模型使用的是阻塞的系统调用 select, poll, epoll 和非阻塞的 socket 的组合。IO 复用的优势在于可以在单个线程中同时处理多个 socket,且不需要在用户线程进行 polling,避免了非阻塞模型中的 CPU 消耗。
以 select 为例,线程在调用 select 后会阻塞,并等待某(几)个 socket 的数据就绪。当有数据就绪时, select 调用会返回可以读取的 socket,用户线程可以接着读取数据并进行对应的处理。处理完成后可以继续调用 select 等待下一次数据就绪。
IO 复用是目前较为常用的一个 IO 模型,在一些大型的项目中都用应用,例如 nginx。同样需要注意的是,在这个模型中,就 recv 调用而言依然是同步的,因为数据从内核空间复制到用户空间的过程中 recv 依然会进行等待。
上面提到的三个系统调用 select, poll, epoll 是历史上先后出现的几个多路复用实现。其中 select 出现最早,实现也最为简单,但是有最多同时处理 1024 个 socket 的限制(可以配置),效率也较低; poll 在 select 之后出现,修复了 select 中的若干问题,包括 1024 个 socket 的限制,而 epoll 是最新出现的,也是效率最高的。
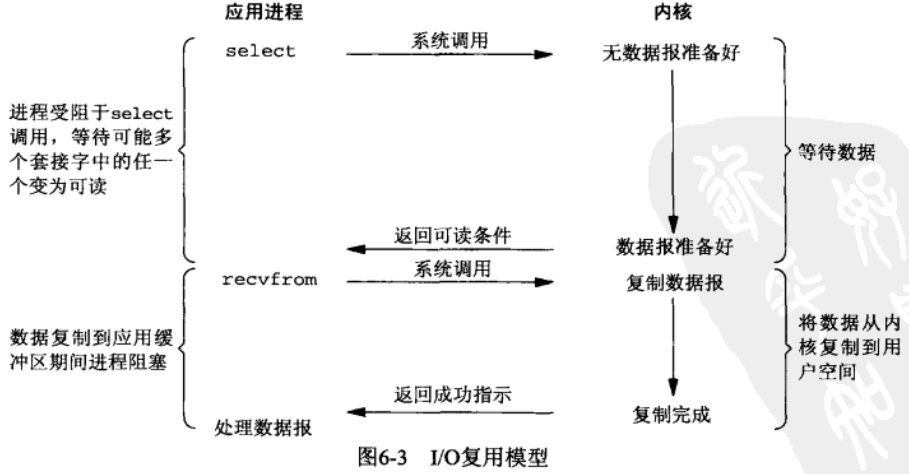
信号驱动 IO
信号驱动 IO (signal-driven IO)模型与上述几个模型的最大不同在于,线程不会直接去询问内核是否有数据可以读取,而是注册一个信号处理函数(signal handler),当内核发现数据就绪时,会产生 SIGIO 信号并发送给用户线程,进而用户线程可以开始读取数据。
这种模型的优势在于不会有任何阻塞(除了调用 recv 时产生的等待),也不需要频繁进行轮询,但 recv 调用依然是同步的。
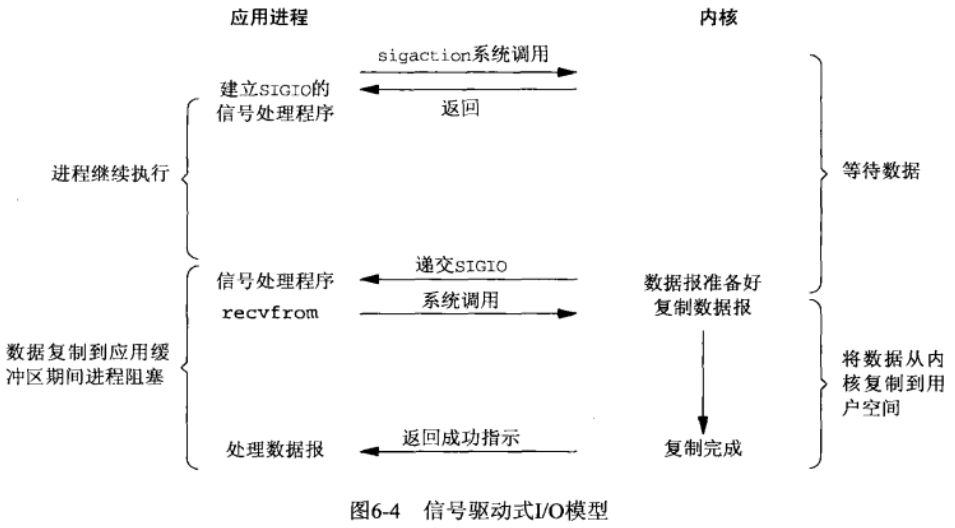
异步 IO
异步 IO (asynchronous IO)模型需要依赖 POSIX 的异步 IO 函数,将 socket,用户线程的缓冲区指针等传递给内核,当内核中检查到有数据就绪并且复制到用户空间的缓冲区之后,通知用户线程进行处理。在这个模型中,用户线程不会等待数据就绪,也不会等待数据从内核复制到用户空间,相比于前几种 IO 模型,异步 IO 的读取操作也不会进行任何等待。
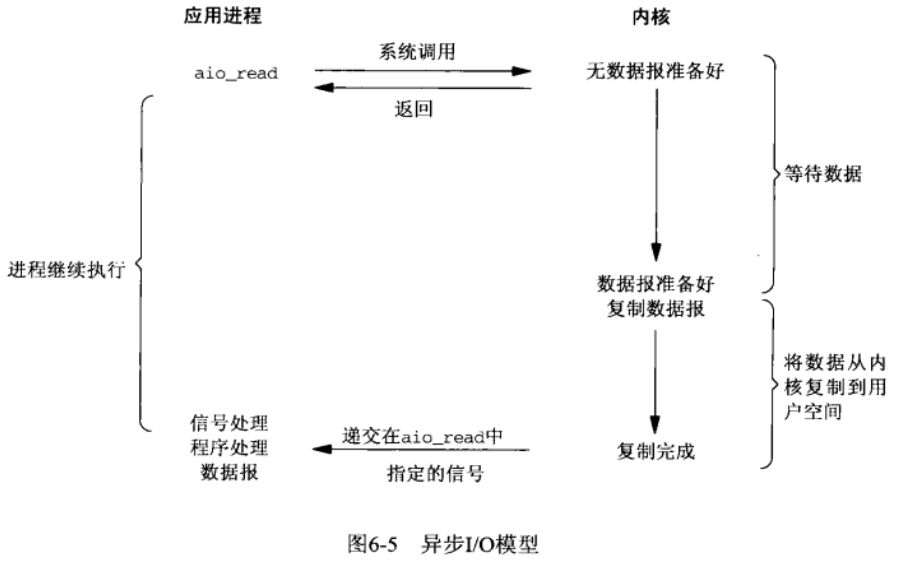
小结
《Unix 网络编程》书中提供了一张总结对比图,描述和对比了几种 IO 模型中用户线程和内核的行为:
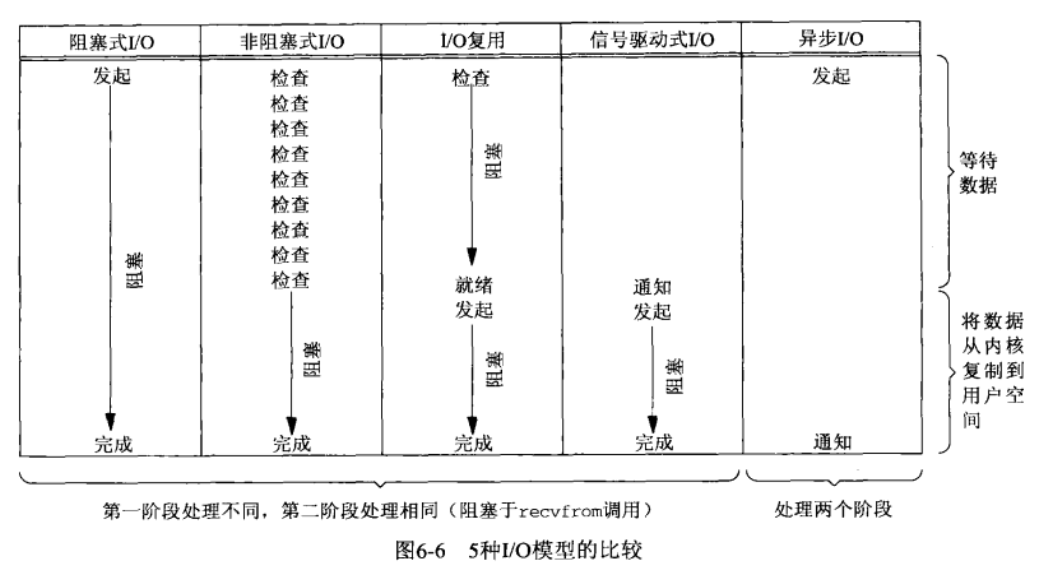
在网络编程中,目前较为常用的 IO 模型应该是 IO 复用模型:一方面 IO 复用可以利用较少的资源高效地处理大量并发 IO(尤其是使用 epoll 的实现),另一方面这种模型相对于信号驱动 IO 和异步 IO 更容易理解(例如不需要理解信号何时触发、由哪个线程处理等问题)。而非阻塞 IO 模型在一些分布式计算的场景中也常见到,例如 MPI 中的 MPI_Isend 函数,在这类场景中,程序通常不需要处理大量的并发 IO,而使用非阻塞 IO 将通信时间与计算时间重叠,可以减少程序的整体耗时。